I had the honor of lecturing for Champlain College's graduate level Malware Analysis course this week. One of the aspects of the lecture was showing off dynamic analysis with my Noriben script and some of the indicators I would look for when running malware.
While every malware site under the sun can tell you how to do malware dynamic analysis, I wanted to write a post on how I, personally, perform dynamic analysis. Some of the things I look for, some things I've learned to ignore, and how to go a little bit above and beyond to answer unusual questions. And, if the questions can't be answered, how to obtain good clues that could help you or another analyst understand the data down the road.Additionally. I've been meaning to write up a malware analysis post for awhile, but haven't really found any malware that's been really interesting enough. Most were overly complex, many overly simple, and most just too boring to write on. Going back through prior incidents, I remembered a large scale response we worked involving a CoreFlood compromise. While this post won't be on the same malware, it's from a similar variant:
MD5: 4f45df18209b840a2cf4de91501847d1SSDEEP: 768:ofATWbDPImK/fJQTR5WSgRlo5naTKczgYtWc5bCQHg:uk6chnWESgRKcnWc5uFSize: 48640 bytes
This is not a ground-breaking malware sample. The techniques here are not new. I want to simply show a typical workflow of analyzing malware and overcoming the challenges that appear in doing so.
There are multiple levels of complexity to this sample, too much for a single post, including ways in which it encrypts embedded data and strings. Therefore, this post will focus on the dynamic artifacts of running the malware and examining the files left behind. On the next post, we'll use IDA Pro to dig deeper into reversing the logic used by the malware.
The analysis in this post will cover analysing malware challenges from various angles. While it discusses the processes of basic dynamic analysis, the emphasis is on seeing malware analysis as a series of logic puzzles. Instead of just running tools, we'll cover various methods to solve these challenges.
I invite any opinions or suggestions on other procedures that could be used to analyze this data. It's how we all learn.
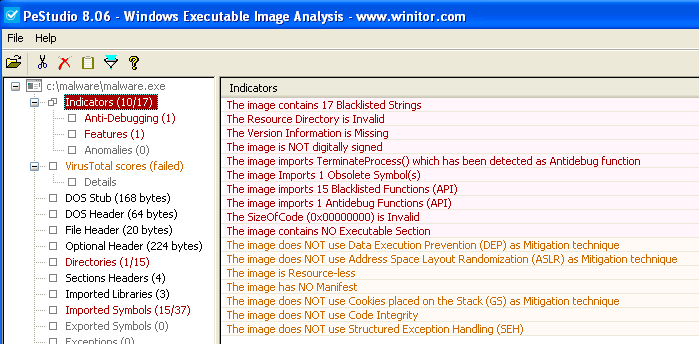
Let's first explore the sample file itself at a basic static level, first. At the advice of my friend and former colleague, Brian Moran (of Bri Mor Labs), I've adapted the use of PeStudio:
PeStudio noted 167 Unclassified strings which could also be obtained via SysInternals Strings. Extracting these strings,
and removing basic API calls, shows:
3etProcAddrControl Panel\Accessibility\TimeOutTimeToWait\system32\winnls.dllkernel32.dllRegOpenKeyExAadvapi32.dllMlLrqtuhA3x0WmjwNM27
I left these specific API and library calls here for a reason (explained in the next post). I'll let you form your own opinion of the severity of these strings. Manual analysis of the executable to find these strings shows that they were at the end of the .rsrc (Resource) section.
Runtime Analysis
I'll start by configuring a VM with basic runtime tools:
FakeNet,
Capture-BAT,
Procmon, and
Noriben. I launch the malware executable and then sit back. After a few seconds I see web traffic appear in FakeNet, so I stop the monitoring and review the results.
After doing some light cleaning of the Noriben results, removing items that are not relevant and duplicate items, I see the following results:
Processes Created:
==================
[CreateProcess] Explorer.EXE:1596 > "%UserProfile%\Desktop\malware.exe"[Child PID: 1548]
File Activity:
==================
[CreateFile] malware.exe:1548 > %AppData%\Adobe\shed\thr1.chm[MD5: e26316552f1b9cbc4943d22bc3d35adc]
[CreateFolder] malware.exe:1548 > %UserProfile%\Local Settings\Temporary Internet Files
[CreateFolder] malware.exe:1548 > %UserProfile%\Local Settings\History
[CreateFolder] malware.exe:1548 > %UserProfile%\Local Settings\Temporary Internet Files\Content.IE5
[CreateFile] malware.exe:1548 > %UserProfile%\Local Settings\Temporary Internet Files\Content.IE5\index.dat[MD5: e736f02e53e55d0869c6ae90c9c8bf00]
[CreateFolder] malware.exe:1548 > %UserProfile%\Cookies
[CreateFile] malware.exe:1548 > %UserProfile%\Cookies\index.dat[MD5: d7a950fefd60dbaa01df2d85fefb3862]
[CreateFolder] malware.exe:1548 > %UserProfile%\Local Settings\Temporary Internet Files\Content.IE5
[CreateFile] malware.exe:1548 > %AppData%\Adobe\plugs\mmc109.exe[MD5: 1e3ab8a8a419459fb8c169c08ea62fcf]
[CreateFile] malware.exe:1548 > %AppData%\Adobe\plugs\mmc109.exe[MD5: 1e3ab8a8a419459fb8c169c08ea62fcf]
[CreateFile] malware.exe:1548 > %UserProfile%\Local Settings\Temporary Internet Files\Content.IE5\SG0UEJSI\showthread[1].htm[MD5: 1e3ab8a8a419459fb8c169c08ea62fcf]
[CreateFile] malware.exe:1548 > %AppData%\Adobe\plugs\mmc109.exe[MD5: 1e3ab8a8a419459fb8c169c08ea62fcf]
[CreateFile] malware.exe:1548 > %AppData%\Adobe\plugs\mmc109.exe[MD5: 1e3ab8a8a419459fb8c169c08ea62fcf]
[CreateFolder] malware.exe:1548 > %AppData%\Adobe\plugs
[RenameFile] malware.exe:1548 > %AppData%\Adobe\plugs\mmc109.exe => %AppData%\Adobe\plugs\mmc61753109.txt
[CreateFile] malware.exe:1548 > %AppData%\Adobe\plugs\mmc109.exe[MD5: 8c4840ab4f47b1b563ce850b12d3c0db]
[CreateFile] malware.exe:1548 > %AppData%\Adobe\plugs\mmc109.exe[MD5: 1e3ab8a8a419459fb8c169c08ea62fcf]
Registry Activity:
==================
[RegCreateKey] malware.exe:1548 > HKCU\Software\Microsoft\Windows NT\CurrentVersion\Winlogon
[RegCreateKey] malware.exe:1548 > HKCU\Software\Microsoft\windows\CurrentVersion\Internet Settings
[RegSetValue] malware.exe:1548 > HKCU\Software\Microsoft\Windows\CurrentVersion\Internet Settings\MigrateProxy = 1
[RegCreateKey] malware.exe:1548 > HKCU\Software\Microsoft\windows\CurrentVersion\Internet Settings\Connections
[RegSetValue] malware.exe:1548 > HKCU\Software\Microsoft\Windows\CurrentVersion\Internet Settings\ProxyEnable = 0
[RegDeleteValue] malware.exe:1548 > HKCU\Software\Microsoft\Windows\CurrentVersion\Internet Settings\ProxyServer
[RegDeleteValue] malware.exe:1548 > HKCU\Software\Microsoft\Windows\CurrentVersion\Internet Settings\ProxyOverride
[RegCreateKey] malware.exe:1548 > HKLM\Software\Microsoft\DownloadManager
There are a few things that pop out at me upon reviewing this. Mostly, there's only one active file in play, our malware.exe. While it creates other files, these dropped files are call executed nor entrenched as additional executable components. That means all functionality that we need is in our malware.exe... does the brevity of those Strings above concern you more now?
I see the tell-tale signs of the malware using Internet Explorer API calls to make HTTP connections. The downloaded file of showthread[1].htm shows an attempt to go out to the internet and download a file.
I see a dropped file to %AppData%\Adobe\shed\thr1.chm with an MD5 value that is not duplicated elsewhere.
I also see multiple writes to a file of %AppData%\Adobe\plugs\mmc109.exe. While all of these files have the same MD5 value, this is not something you can trust; those MD5s are assigned by Noriben after runtime. So, the content could have changed between each write. There were actually dozens of continual writes to that same file, many of which were removed here for brevity. Could this be a keylog file?
But, why does this file almost always end up with the same hash value as the downloaded file, showthread[1].htm, except for one instance where it has another unique hash value?
And why is not a single file deleted?
Curiouser and Curiouser.
Registry analysis shows little that pops out. The HKCU\...\Internet Settings keys are written normally whenever Internet Explorer is launched benignly. Unless there's something later to tell me these were used directly by the malware, I'll ignore them as background noise associated with an action performed by the malware (downloading a file).
Let's switch gears to the FakeNet network capture output, stored as a PCAP file. Opening this file in WireShark I see two DNS requests: adobe.com and presentpie.vv.cc. Following TCP traffic, I then see HTTP requests going to each of these respective domains:
adobe.com:
presentpie.vv.cc:
You'll note that all of the HTTP GET requests are for the same URI, containing "t=332864" which is a bit of an oddity. If you have the ability to create a random number to put in this field, why not do so?
At this point, there are a few things that we need to determine:
- What is the purpose of that %AppData%\Adobe\shed\thr1.chm file?
- Is the contents of showthread[1].htm what FakeNet would send?
- Why is %AppData%\Adobe\plugs\mmc109.exe almost always the same hash value as showthread[1].htm?
- Why was mmc109.exe renamed to mmc61753109.txt?
This is the point where most automated analysis tools, and many analysts, stop. But, there's a whole cornucopia of cool stuff left undiscovered.
Level 2 (Digging Deeper)
Opening thr1.chm up in a hex viewer shows very interesting contents:
At only 49 bytes, and only written at initial runtime, my first thought is that this is configuration data used by the malware. The data is obviously not Base64 encoded, so maybe a basic XOR routine? I see little patterns, no repeated sequential characters, and very few repeated bytes, so likely not a single-byte XOR. We'll need to do static analysis to figure out the structure and purpose of this file completely
Second, let's view the showthread[1].htm file. A quick visual scan shows that it's a standard FakeNet HTML page:
<p class=MsoNormal>This is the help file for <span class=SpellE>FakeNet</span>
version 1.0.<span style='mso-spacerun:yes'> </span>This program must be run
with administrator privileges. <span style='mso-spacerun:yes'> </span>If you
like this tool and are interested in malware analysis, please consider
purchasing Practical Malware Analysis from No Starch Press.<span
style='mso-spacerun:yes'> </span>It contains lots of great information to help
you become a skilled malware analyst.</p>
Running an MD5 hash of this value gives 1e3ab8a8a419459fb8c169c08ea62fcf, the same value we see repeated in our Noriben results. This makes a bit of sense. The malware is requesting a file named showthread[1].htm from some remote site, expecting it to be a legitimate, un-encrypted executable, and copies it to %AppData%\Adobe\plugs\mmc109.exe. This downloaded file is very likely a second-stage trojan.
But, why does mmc109.exe sometimes have a different hash value? Upon ending my runtime, the file had the 8c4840ab4f47b1b563ce850b12d3c0db hash value. Opening it in a hex editor shows a possible answer:
This file is encrypted. The style looks similar to that seen in thr1.chm, and its very likely that the same encrypted/decryption routine was used for both files.
This suggests that the malware sample downloads a file, encrypts it, and saves it to mmc109.exe. The hash varies possibly because the malware routinely decrypts it for execution, then re-encrypts it afterward. Maybe we saw no additional processes created because it wasn't a valid executable? Can we test this? Absolutely! Instead of using the FakeNet fake HTML page, replace it with calc.exe and re-run the malware:
Processes Created:
==================
[CreateProcess] Explorer.EXE:1596 > "%UserProfile%\Desktop\malware.exe"[Child PID: 2000]
[CreateProcess] malware.exe:2000 > "%AppData%\Adobe\plugs\mmc188.exe"[Child PID: 856]
[CreateProcess] malware.exe:2000 > "%AppData%\Adobe\plugs\mmc188.exe"[Child PID: 444]
Upon running the malware, the Windows calculator opens. And opens again... and again. Additionally, we also now know that the three digit number after 'mmc' varies per runtime.
The last question was to find the purpose of the mmc61753109.txt file. We see the malware rename mmc109.exe to this file, then create another mmc109.exe. The mmc61753109.txt file had the same MD5 hash value of 8c4840ab4f47b1b563ce850b12d3c0db, and a quick look in the hex editor shows that it's the encrypted version of the downloaded file. Maybe it's a backup of the second-stage malware?
From this level of analysis we now know what the showthread[1].htm file is and it is copied to mmc109.exe, but we're left with a few more questions:
- What is the encryption routine used for thr1.chm and mmc109.exe?
- Why does the malware rename mmc109.exe to mmc61753109.txt?
- Why does the malware first make a network connection to Adobe.com? What does that POST value mean?
- Why is none of this functionality apparent based on the strings extracted from the malware?
Some of these can only be solved via static analysis. Some analysts would likely stop at this point, noting these questions for future analysis.
We won't :)
Level 3 (Memory Analysis)
The big question is how much of these questions can we answer based on dynamic analysis, and which require us to use a tool like
IDA Pro or
Hopper to reverse the malware in static analysis, or at least a Debugger to step through the malware's operation?
We can take an initial stab at the encryption routine, but it won't be as effective as a static analysis. To do this, we have to define the constants and the variables in the encryption routine. We have a known decrypted set of data (the FakeNet HTML output), and a known encrypted version of the file. If you run the malware again, you'll find the encrypted results are identical, suggesting that there's no random seed used in the encryption, or that the data is simply encoded.
Encoding versus Encryption is splitting hairs on routines. Typically if data is transformed via a simple byte-by-byte operation (add, subtract, XOR), we consider it encoding. If data is transformed via a cipher pad, key scheduler, or similar routines, then we consider it encryption. For the sake of this post, we'll consider everything encryption until we know better.
We can also try and determine if the encryption routine is stream-based or block-based. Take the original FakeNet document and leave the first 16-bytes intact. Modify the 16-bytes following those to a series of all the same character. Re-run the malware and analyze the encrypted results. You'll find the first encrypted first 16 bytes remain the same, while the modified 16-bytes have changed... and the remainder of the file is identical to the first run. You can then repeat this by changing a single byte in the first 16-bytes, from the end to the beginning, and seeing how much of the encrypted text changes. You'll basically be narrowing the size of your encryption window over time until you see how large it is.
This is a long process, but it will eventually tell you that data is encrypted 4-bytes (DWORD) at a time. It's also something we could have determined with static analysis in just 30 seconds :)
As far as the strings, we'll need to shift our focus to memory analysis with
Volatility:
> v.py -f XP_VM.vmem pslist
Volatile Systems Volatility Framework 2.3_beta
Offset(V) Name PID PPID Thds Hnds Sess Wow64 Start Exit
---------- -------------------- ------ ------ ------ -------- ------ ------ ------------------------------ -----
0x829c8830 System 4 0 56 2290 ------ 0
0x820ab1f8 malware.exe 1548 1596 6 3255 0 0 2014-02-08 17:06:10 UTC+0000
With the malware PID found, let's dump the executable from memory space. During runtime, malware may decode data in-place from within its own data. If so, the latest version of the executable from RAM will contain the same code but decoded strings. To do this, we'll use Volatility's procexedump to carve out the usable executable space from memory. Alternatively, procmemdump can be used to do the same, but with the inclusion of slack space within the memory heaps.
E:\VMs\XP_VM>v.py -f XP_VM.vmem procexedump -p 1548 -D .
Volatile Systems Volatility Framework 2.3_beta
Process(V) ImageBase Name Result
---------- ---------- -------------------- ------
0x820ab1f8 0x00400000 malware.exe OK: executable.1548.exe
With this file dumped, I'll do a quick strings/grep to see if it contains any of the static indicators I saw in Noriben's output:
> strings executable.1548.exe | grep -E -i "presentpie|mmc|shed"
shed
shedexec:thr1:
\shed
mmc
delshed
mmc_install
delshedexec
shedexec
shedscr:3:120 http://presentpie.vv.cc/showthread.php?t=332864
Now we're cooking with fire. Dumping strings from this new executable gives us:
id=
solutions.html
oodmansof
ansoft
shed
scr:
ZZZZ
shedexec:thr1:
ZZZ
Hui
Member Window
\Ad
obe
\shed
.cer
.e
\msh
.ex
err.log
SystemDrive
POST /
HTTP/1.1
Host:
User-Agent: Opera/10.80 Pesto/2.2.30
Content-Type: application/x-www-form-urlencoded
Content-Length:
User-Agent: Opera/10.60 Presto/2.2.30
mmc
.txt
.exe
open
delshed
exec:thr1
htt
t\*.*
.chm
mmc_install
runas
.dll
delshedexec
shedexec
downadminexec
xec2
User-Agent: Opera/10.60 Presto/2.2.30
ABCDEFG
local
explorer.exe
accuratefiles.com
elsoplongt.com
et-treska.com
lulango.com
shedscr:3:120 http://presentpie.vv.cc/showthread.php?t=332864
Much better!
Based on this level of analysis, we now know a lot more about the malware. We have a very good notion that the initial malware.exe was a loader that decrypted an internal executable and injected it into memory. We also know that the injected executable is responsible for network connections.
However, what happened to the original strings we pulled out? They're not in the new display! And can we figure anything else out about the encryption? We're going to need to up our game a bit to see what's going on.
Level 4 (Visual Analysis)
The original executable was 48640 bytes. What we pulled from memory was 34304 bytes. There are 14336 (0x3800) bytes unaccounted for. The process we pulled out of memory could be a second executable injected by the malware, in which case the original strings from the loader were cast off in memory like a snake shedding its skin.
Scratching my head a bit, I take the original malware executable and just page through it with a hex editor, comparing sections side-by-side with the extracted executable. If you've ever taken any of my malware analysis training, I emphasize the power of the human eye to detect patterns better than any software. This proves to be the case here.
Notice the similarities? The extracted file from Volatility is a series of PADDINGXX, which is STANDARD and BENIGN for executables with resources. (I've read way too many analysis reports that called this out as an indicator). Look at the encrypted file and you'll see a series of ..DD...X repeating in a pattern. Comparing bytes above and below also show series of two-byte segments that are the same. Interesting. Could be an encoding routine that skips certain bytes, or a multi-byte XOR with null characters in the key. Wherever there's a null byte in an XOR key, the original data will remain, so this could be the case.
This overlap was, roughly, at the 95% of the decrypted file and the 80% mark of the encrypted file, which further suggests that remaining data in the original file was a shell used to inject an executable. Once launched, and extracted by Volatility, all we recovered was the injected portion.
Scrolling up through the decrypted file, I see a block of configuration data jump out at me. Scrolling up to roughly the same point in the original file, I see what could be its encrypted values:
There may be a few bytes off between the samples, as is the case here (such as the row of 0x01's in the encrypted version), but your eye should adjust for these and see the data around it.
Of note is the large block of null data below the value on the decrypted side. If there's an encryption key through an XOR operation, you'll typically see it on the encrypted side wherever there's a null block on the decrypted. And here, we see a pattern of 0x0000BC85 over and over, which could be a 4-byte XOR key.
Based on this, we have a fair idea that the malware contains an encrypted executable, which is injected on runtime. This injection contains a configuration block containing multiple domain names, some not seen during runtime. We also have good evidence that the encoding was done via a 4-byte XOR key of 0x0000BC85 (or 0xBC850000, or 0x850000BC, or 0x00BC8500).
Conclusion
Dynamically analyzing malware is a varied art and science. Most of the industry is worried about the high level indicators, shown in the first portion of this analysis. However, this often leaves behind more questions than it answers. There are a lot of very important items that we would have completely missed had we not dug deeper.
The art of analysis is not just from being able to look at activity and understanding it. It comes from being able to see a logical problem in front of you and understanding how to overcome the challenge. Each sample is different, each challenge is unique, and techniques that work for this malware will be useless on the next.
That's the joy of malware analysis.
Stay tuned for Part 2: Static Analysis (a.k.a. Brian procrastinating his book writing). There, we'll use IDA Pro (or Hopper) to find encrypted strings, work out the loader logic, figure out why and how it's dropping files, and see what other fun things the malware does.
Updates:
11 Feb 14 - Fixed one hash, reworded encoding segments, thanks to feedback from Mark Heidrick